Meta社のAI基盤研究(FAIR)チームはこのほど、テキストと画像が混在したコンテンツを理解・生成できる混合モーダルAIモデル「Chameleon」を発表した。人間の審査員によって評価された実験では、Chameleonの生成出力はGPT-4よりも51.6%、Gemini Proよりも60.4%で好まれた。
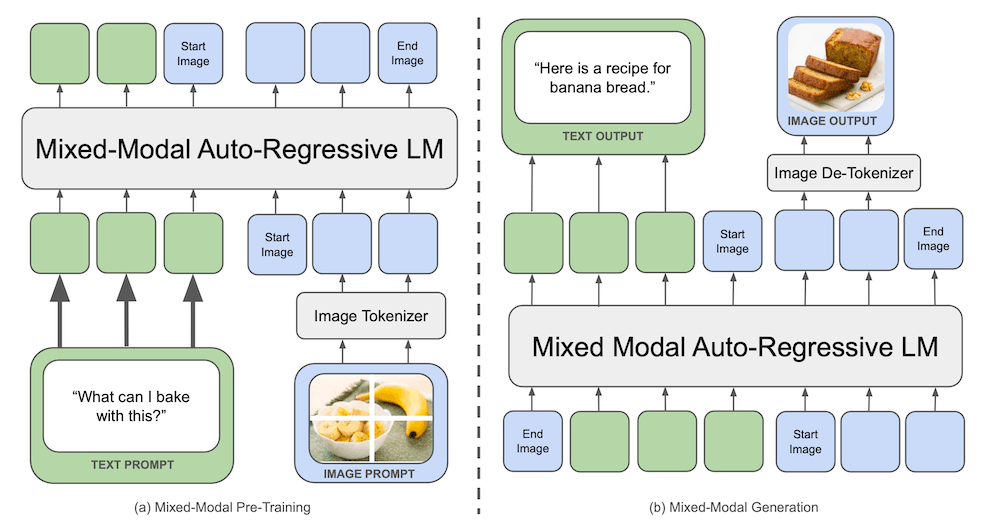
Chameleonは、2つのモダリティに別々のエンコーダーとデコーダーを使用する、多くの画像・テキスト混合AIモデルとは異なる。その代わりに、Chameleonはテキストと画像の両方を単一のトークンベースで表現し、画像とテキストの混合シーケンスでエンドツーエンドで学習する。Meta社は、70億のパラメータを持つChameleon-7Bと、340億のパラメータを持つChameleon-34Bの2つのサイズのモデルをトレーニングした。どちらのモデルも、4兆トークンを超えるテキストと画像の混合データで事前にトレーニングされ、その後、より小さなデータセットでアライメントと安全性を微調整した。ベースラインモデルと比較する人間の判定に加え、Meta社はいくつかのベンチマークでChameleon-34Bを評価し、Chameleonが視覚的質問応答 と画像キャプションのタスクで最先端の性能を達成したことを指摘した。Meta社によれば、次のように述べている。
画像を個別のトークンに量子化し、混合モーダルデータをゼロから学習することで、Chameleonは画像とテキストを共同で推論することを学習します。同時に、Chameleonは初期融合モデルを安定的かつスケーラブルに学習する新しい技術を導入し、これまでそのようなアプローチのスケールを制限していた重要な最適化とアーキテクチャ設計の課題に対処しています。
Metaチームは、8B以上のモデルパラメータや1T以上のデータセットトークンをスケーリングする際、不安定性のためにChameleonをトレーニングするのは「困難」であると指摘した。特に、モデルの重みが両方の入力モダリティで共有されているため、「各モダリティがベクトル規範を増加させることで他方と競合しようとし」、最終的に規範がモデルで使用されている16ビット浮動小数点表現の範囲外に移動してしまうことがわかった。解決策は、モデル・アーキテクチャに正規化操作を追加することであった。
Chameleonの学習と推論。画像ソース:メタ研究論文
Chameleonを使った自己回帰出力生成にも、「ユニークな」性能上の課題があった。まず、混合モード出力を生成するには、モードごとに異なるデコード戦略が必要となるため、出力トークンはプログラム制御フローのためにGPUからCPUにコピーされなければならない。また、モデルは単一モード出力(例えばテキストのみ)の生成を求められることがあるため、他のモダリティのトークンを覆い隠したり無視したりする機能が必要となる。これらの問題を解決するために、Metaはモデルのためのカスタム推論パイプラインを実装した。
この研究についてのXのスレッドで、Chameleonの共著者であるArmen Aghajanyan氏はこう書いている。
我々がChameleonで学んだことの核心の一つは、モダリティの意図する形はそれ自体がモダリティであることです。視覚的知覚と視覚的生成は2つの異なるモダリティであり、そのように扱われなければなりません。したがって、知覚に離散化トークンを使うのは間違っています。
別のスレッドでは、AI研究者のNando de Freitas氏が、ChameleonのアーキテクチャがDeepMindのGatoモデルと似ていると指摘し、「これがMIMO(マルチモーダル入力マルチモーダル出力モデル)の究極のアプローチになるのか、それとも他に試すべきことがあるのか?」と疑問を投げかけている。
Meta社は安全上の懸念を理由にChameleonを公には発表しなかったが、混合モード入力をサポートするものの画像出力を生成できないモデルの修正版を発表した。これらのモデルは、リクエストに応じて「研究専用ライセンス」の下で使用できる。