Uber社は、DynamoDBとblobストレージから新しい長期的なソリューション、LedgerStoreと名付けられた専用のデータストアにすべての支払いトランザクションデータを移行した。同社はコスト削減を模索しており、以前はホットデータ(12週間前のもの)を保存するためのDynamoDBの使用を削減していた。この移行により、大幅なコスト削減とストレージアーキテクチャの簡素化が実現した。
Uber社は2017年に決済プラットフォームであるGulfstreamを構築し、ストレージにDynamoDBを使用していた。ストレージコストの上昇により、DynamoDBは最新のデータ(12週間分)のみに使用され、古いデータはUber社が社内で作成したS3ライクなサービスであるTerraBlobに保存されていた。
その一方で、同社はデータの完全性を保証した金融取引を保存するための専用ソリューションの開発に着手した。Uber社の技術責任者であるKaushik Devarajaiah氏は、特注のデータストアを作成する際のユニークな課題について説明する。
LedgerStoreはUber社のイミュータブルストレージソリューションであり、これらのトランザクションデータの完全性を保証するために、検証可能なデータの完全性と正しさの保証を提供します。台帳がUber社におけるあらゆる財務イベントやデータ移動の真実のソースであることを考慮すると、様々なアクセスパターンからインデックスを介して台帳を検索できることが重要です。このため、数十億の台帳にインデックスを付けるために、数兆のインデックスが必要になります。
LedgerStoreは、強力で最終的に一貫性のあるインデックスをサポートしている。強力で一貫性のあるインデックスの場合、データストアは2段階のコミットを使用する。まずインデントを保持し、次にレコードを保持する。最後に、レコードの書き込みが成功した場合、インテントは非同期にコミットされるか、失敗した場合はロールバックされる。インテントの書き込みが失敗すると、整合性保証がサポートできないため、挿入操作全体が失敗する。読み込みの間、コミットされていないインテントを持つ書き込みは、(レコードの読み込みが成功した場合)コミットされるか、(レコードの読み込みが失敗した場合)非同期で削除される。LedgerStoreは、MySQLの上に構築された分散データベースである自社開発のDocstoreデータベースのマテリアライズドビューを活用することで、最終的に一貫性のあるインデックスを実装している。
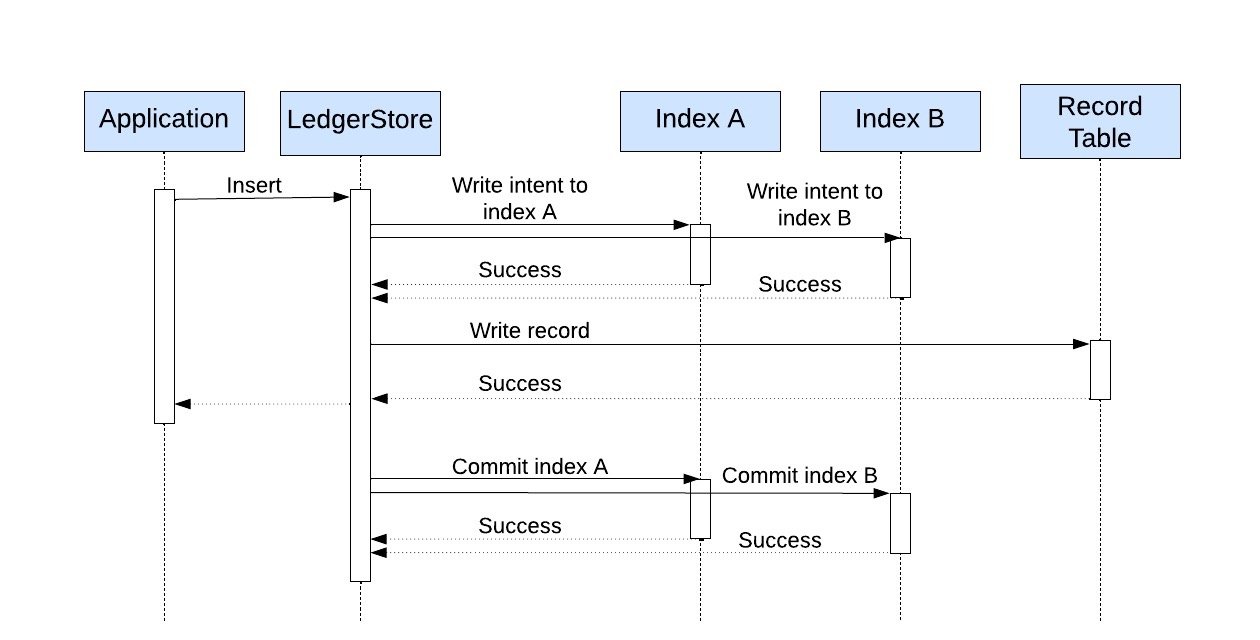
強力で一貫性のあるインデックスのための2段階コミット書き込み(出典:Uber Engineering Blog)
古い台帳データをコールドストレージにオフロードするため、LedgerStoreはタイムレンジインデックスを使用して時間クエリをサポートしている。Uber社は、DynamoDBとDocstoreをタイムレンジインデックスの保存に使用していた。当初のソリューションは、DynamoDBで2つのテーブルを利用し、1つは書き込み用に最適化され、もう1つは読み取り用に最適化されていた。この設計はDynamoDBのキャパシティ管理によって決定され、ホットパーティションやスロットリングを回避していた。新しい設計では、1つのテーブルを持つDocstoreデータベースを使用し、効率的な読み取りのためにプレフィックススキャンを活用している。
LedgerStoreはインデックスのライフサイクル管理をサポートし、インデックス定義が変更された場合にデータの再インデックス作成を自動化する。このプロセスでは、新しいインデックスを作成し、古いインデックスのデータをバックフィルし、関連する検証をし、インデックスを交換し、古いインデックスを削除する。
コールドストレージからのインデックスバックフィル(出典:Uber Engineering Blog)
ペタバイトの金融取引データをLedgerStoreに移行する際、同社はユニークな課題に直面した。LedgerStoreへの移行の正確性、本番環境でのパフォーマンスと拡張性を保証するために、シャドー検証とオフライン検証をした。シャドー検証では、GulfstormはDynamoDBとLedgerStoreにデータを二重書き込みし、2つのデータストア間で読み取りによって返されたデータを比較した。
さらにUberr社は、Apache Sparkで実行される増分バックフィルジョブと組み合わせて、履歴データのオフライン検証を実施した。バックフィルプロセスだけでも大きな問題があり、このプロセスで発生する負荷は通常の本番負荷の10倍に達し、プロセス全体では3カ月を要した。エンジニアはプロセスを制御し、あらゆる問題を軽減するために、プラットフォームが処理する本番トラフィックに基づいて処理速度を調整する動的レート制御や、重大な問題が発生した場合にプロセスを迅速に停止する緊急停止など、いくつかの手段を使用した。
最後に、チームはロールアウトに対して保守的なアプローチを取り、LedgerStoreでデータが見つからない場合に備えてDynamoDBからデータを取得するフォールバックを採用した。全体的な移行は成功裏に完了し、移行中も移行後もダウンタイムや停止は発生しなかった。LedgerStoreへの移行は大幅なコスト削減をもたらし、年間600万ドル以上の節約になると見積もられている。
**UPDATE:**このニュースが発表されて以来、Hacker News とRedditで議論が巻き起こり、何百ものコメントが投稿された。多くのユーザーが、クラウドプロバイダーのサービスを利用することと、自社でデータベースを含むソリューションを構築することの長所と短所について議論した。スタッフの給与、メンテナンスのオーバーヘッド、データ移行に費やされる労力を考慮すると、カスタムデータストアを展開することが正当な投資対効果をもたらすかどうかを疑問視するユーザーもいた。