Thoughtworks社のデータ&AI担当VPであるDanilo Sato氏は、QCon Londonのプレゼンテーションで、データ製品の実装の際にドメイン駆動設計とチーム・トポロジーの原則を適用することの重要性をあらためて強調した。これにより、データの責任が開発者に「委ねられる」複雑な状況おいても、効果的なデータのカプセル化が保証される。
カンファレンス・トラック「Architectures You've Always Wondered About」の主催者であるCassie Shum氏は、カンファレンスの中で次のように述べた。
今日のデータの重要性を考えると、AIへの移行が進んでいる中でこのプレゼンテーションがこのトラックの一部にならないのは想像できません。
Sato氏はまず、さまざまな業界(伝統的なものからストリーミングまで)のデータ・アーキテクチャをいくつか紹介し、データ・インジェスト(バッチまたはストリーム)、データ・パイプライン、ストレージ、コンシューマー、分析といったおなじみのコンポーネントがあることを強調した。
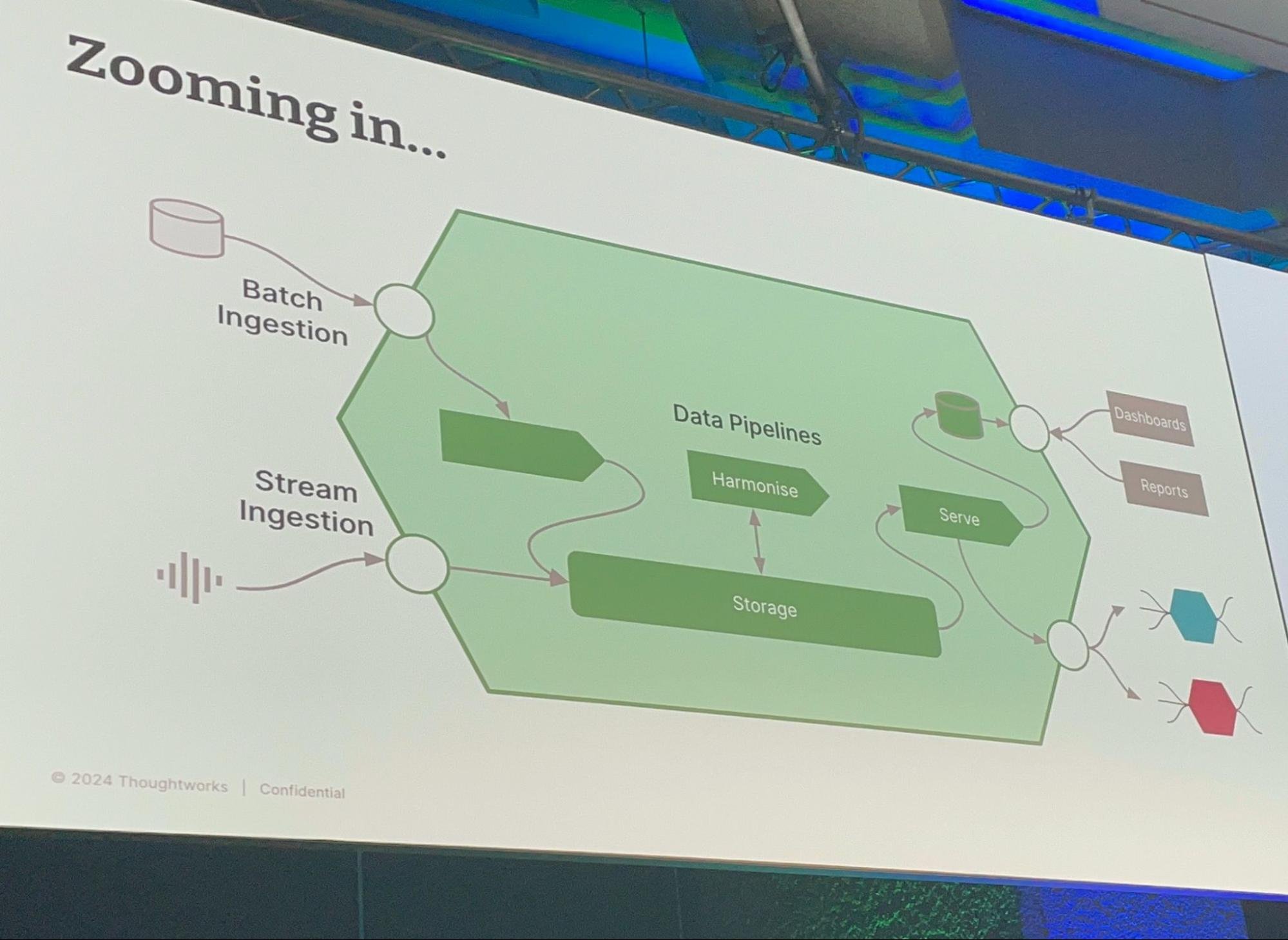
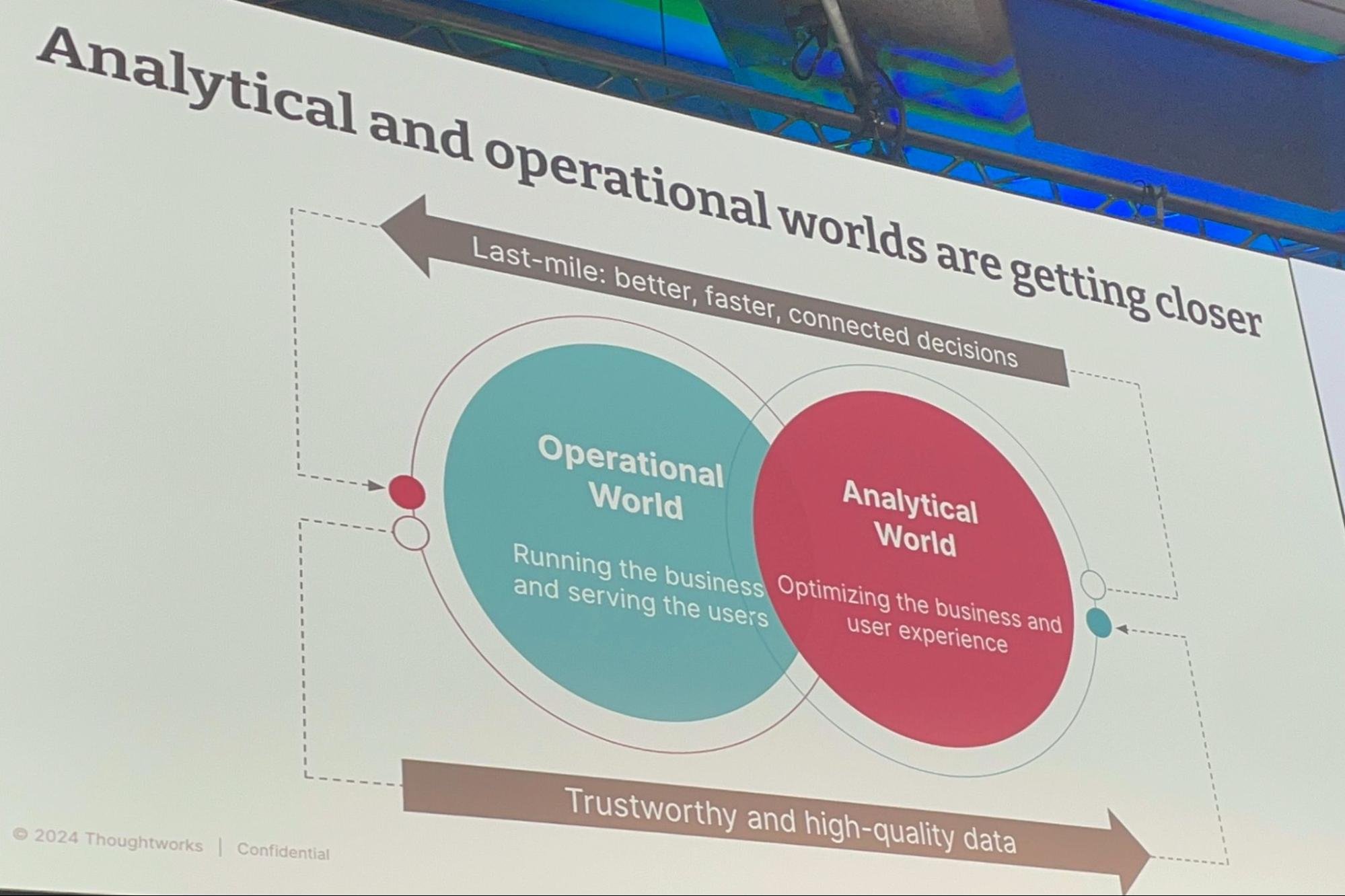
さらに、データ宇宙に存在する2つの「世界」、すなわち運用と分析は、より密接な関係を築きつつある。同氏は、基礎となるテクノロジーではなく、データプロダクトの概念を用いることの重要性を強調した。「データプロダクトのためのアーキテクト、あるいはプロダクトとともにアーキテクトする」ということは、データエンティティをバージョン管理や契約といった実際のプロダクトのように扱うことを意味している。
Sato氏は、どのDBMSを使うかを選択するだけだった2000年代の単純な決定から、機械学習AIとデータ(MAD)として認識されている現在に至るまで、技術的な状況は進化し続けていると指摘した。進化にもかかわらず、彼は”モデリングは以前難しい”と強調した。「特に、モデルの有用性はユーザーが解決しようとしている問題に依存し、その効率を客観的に評価する方法がないからだ。
George E.P. Box氏 すべてのモデルは間違っているが、いくつかは有用である
Sato氏は、Gregor Hohpe氏の「アーキテクト・エレベーター」という概念(アーキテクトは、ビジョンから実装の細部に至るまで、企業のさまざまなレベルでコミュニケーションをとらなければならない)から出発し、データアーキテクチャの懸念事項として、下位から上位に渡り留意すべき点を紹介した。
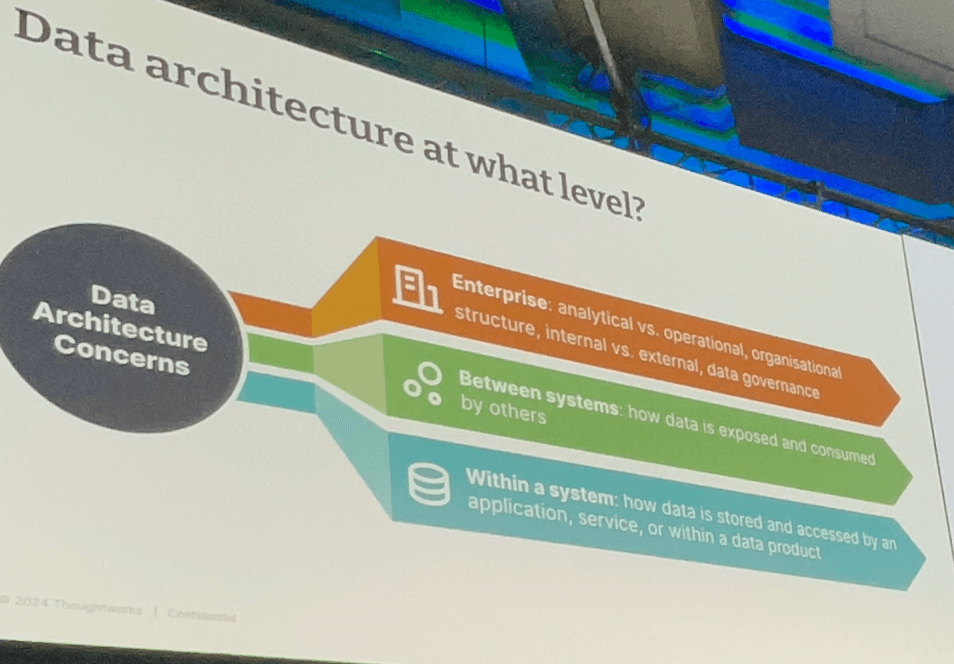
下位レベルとは、システム内を流れるデータのことである。従来は「データにアクセスさせてくれれば、分析は私がやる」といったカプセル化を解除することが許容されてきたが、製品視点で考える場合にはボリューム、ベロシティ、一貫性、可用性、レイテンシ、アクセスパターンなどの運用面以外にも考慮すべき側面がある。
分析的側面とは、データ製品、データを管理・共有するための社会技術的アプローチを指す。
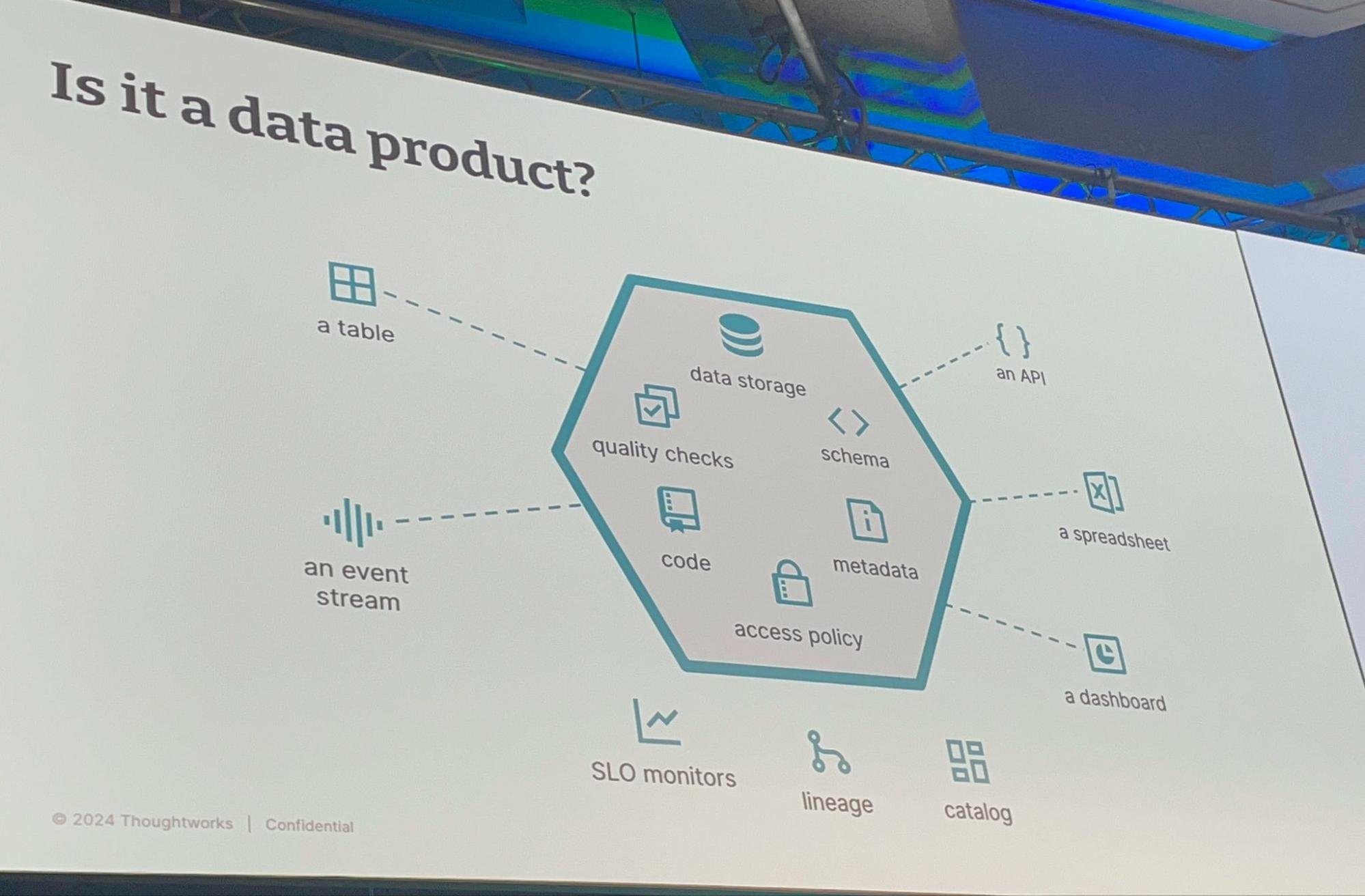
データをよりカプセル化し、データフローを処理する入力、出力、制御ポートを備え、バージョン管理可能なデータ製品仕様の提供が必要である。システム内のデータがうまくカプセル化されていれば、外部に影響を与えることなく、基盤となるデータベースを置き換えできる。すべてのアーキテクチャの決定と同様に、実装に使用するデータベースの種類を決定する際には、トレードオフを考慮する必要がある。
中間レベルとは、システム間を流れるデータのことである。 このレベルでの決まりは、より広い範囲に影響を及ぼす。他のシステムにデータを公開することは、尊重されるべき契約、つまりデータ製品のAPIを公開することになる。このデータ契約で考慮すべき点は、サポートされるデータ形式、組織横断的な標準、データのスキーマ、メタデータ、発見可能性などである。
動きのあるデータについて話す場合、2つの主要なパラダイムがある。バッチ(期間限定のデータセット)とストリーミング(無限のデータセット)。後者の場合、データが遅れたり、処理に失敗した場合に備えて、特別な制御を加える必要がある。データメッシュの本では、3種類のデータ製品について言及している。ソースに沿ったデータ製品、集約されたデータ製品、消費者に沿ったデータ製品である。

上位レベルは、組織構造とデータガバナンスという企業レベルに焦点をあてる。 このレベルでは、ビジネスがどのように組織化されているか、どのようなドメインがあり、誰がそれを所有しているか、そしてそれらのドメイン間の状況についてより詳しく説明する。DDDによる戦略的設計は、これらの疑問への回答に役立つ。
分散型モデルに移行するには、たとえチームが複数のプロダクトを所有していたとしても、データプロダクトの長期的な所有権を確保する必要がある。セルフサービス・プラットフォームは、まとまりのあるデータ製品を実装する鍵である。これによって、製品構築時のアプローチがばらばらになることを避け、ガバナンスの導入を容易にできる。

企業レベルでは、データガバナンスについても語ることが重要だ。所有権、アクセシビリティ、セキュリティ、データ品質について、企業はどのように対処しているのだろうか?ガバナンスは人とプロセスにも関わるものであることを踏まえ、Sato氏はデータ周りのチーム編成のヒントとしてチーム・トポロジーを挙げた。
彼は最後に、"データについて考えることは、システム内のデータ、システム間のデータ、企業レベルのデータなど、多くのことを考えることである "と述べた。
ビデオ・オンリー・パスでQCon Londonの録画講演にアクセスする。